AI-native concept · self-initiated
almanac
An enterprise AI knowledge engine. Employees ask a question in plain language and get a synthesised, cited answer drawn from the company's own documents, wikis, and tickets. I took it from problem framing through research, IA, and a clickable prototype, with answer-provenance and trust as the central design problem. An answer you can't verify is an answer no one will act on.
A knowledge engine that answers in your company's own words, and shows its sources.
TL;DR · Concept Summary
Inside most companies, the answer to a question already exists in a doc, a wiki page, a closed ticket, or a Slack thread. Finding it means knowing where to look and who to ask. Almanac is a self-initiated concept that lets anyone ask a question in plain language and get a single synthesised answer assembled from the company's own sources, with every claim cited and clickable. I ran the full process: jobs-to-be-done interviews, an audit of how knowledge actually moves through an org, IA from a content model, three core flows, then polished hi-fi screens of the designed product. Answer-provenance is the load-bearing trust mechanism throughout.
Concept · self-initiated · not client work
Type
AI-native product concept
Role
Sr. UX Lead (end-to-end)
Timeline
Self-initiated · 2026
Platform
Responsive web, desktop-first
Tools
Figma, content modelling, JTBD interviews
process
Almanac is a self-initiated concept, not a client engagement. I chose enterprise knowledge because it's a problem every company has and almost none have solved well: institutional memory is real, valuable, and effectively unsearchable. It's also a sharp test of AI-trust design. Generative answers are easy to produce and easy to distrust. The design challenge is making an AI answer one a domain expert will actually rely on, which means provenance, not polish, is the product.
Knowledge work runs on questions: 'how did we handle this last time?', 'what's our policy on X?', 'who decided this and why?'. Today those questions get answered by interrupting a colleague, digging through a wiki that's six months stale, or giving up. The interesting design problem isn't building a search box. It's designing an answer surface trustworthy enough to replace the colleague-interrupt.
Why this concept
Three reasons. It's a near-universal enterprise pain with no good incumbent. Answer-provenance is a genuinely hard, genuinely important trust-design problem. And it lets the case study show a process that's jobs-to-be-done and content-model-led, different from the ethnographic Slate or the decision-led Crux.
Meet the people with the questions, and the answers.
Knowledge has a supply side and a demand side. Most people are on the demand side: they have a question and need an answer now. A few are domain experts who hold the answers and get interrupted for them all day. And someone owns whether the knowledge base is trustworthy at all. Almanac has to serve the asker without burning out the expert.
Sam Okonkwo
Knowledge Seeker · primary
A mid-level employee in sales, ops, support, or engineering, who hits questions all day that someone, somewhere in the company, has already answered.
goals
- Get a trustworthy answer without interrupting a busy colleague
- Know the answer is current, not from a doc that's two reorgs old
- See where the answer came from so they can defend the decision
frustrations
- Wiki search returns 40 stale pages and none of them answer the question
- The real answer lives in a closed ticket or a Slack thread they can't find
- Ends up asking a colleague and feeling like they're wasting everyone's time
jobs to be done
“When I hit a question someone has answered before, I want a trustworthy answer fast, so I can keep moving without interrupting an expert.”
Wiki search · Slack · Google Drive · asking around
Dr. Lena Hartmann
Domain Expert
The person everyone pings. Holds deep knowledge in her head and in scattered docs, and loses hours a week to questions she's answered a dozen times.
goals
- Stop answering the same question for the tenth time
- Make sure people get the right answer, not a half-remembered version
- Keep her actual job from being buried under interruptions
frustrations
- Constant context-switching to answer questions kills deep work
- When she's out, the team is stuck because the knowledge is in her head
- Documentation she writes goes stale and nobody finds it anyway
jobs to be done
“When I've answered something once, I want it captured and reusable, so I'm not the single point of failure for my own expertise.”
Her own head · scattered docs · Slack DMs
Marcus Webb
Knowledge Admin
Owns the knowledge base, the wiki, the intranet. Accountable for whether any of it is trustworthy, and quietly aware that most of it isn't.
goals
- Make the knowledge base something people actually trust and use
- See what people are asking that the docs don't answer
- Keep answers from drifting out of date silently
frustrations
- No visibility into what questions are going unanswered
- Stale content erodes trust, and trust is almost impossible to win back
- Can't tell which docs matter and which are dead weight
jobs to be done
“When knowledge goes stale or a gap appears, I want to see it, so I can fix the base before people stop trusting it.”
CMS · analytics · the wiki nobody reads
in their words
“I know we've solved this before. I just can't find where.”
“Search gives me documents. I wanted an answer.”
“I'm answering the same Slack question for the tenth time.”
“Half the wiki is wrong and I can't tell which half.”
“If it's stale once, people never trust it again.”
I followed a question through the company.
Jobs-to-be-done interviews
Rather than ask people what they think of their wiki, I traced real questions: what someone needed to know, where they looked, how long it took, and what they did when they gave up. Six jobs-to-be-done interviews across roles, reconstructing the actual path of a question from 'I need to know X' to 'I have a usable answer', or to abandonment.
Participants
6 across roles
Method
Jobs-to-be-done interviews
Traced
Real questions, end to end
Captured
Path, time-to-answer, give-up point
The life of a question
Mapping one question's journey showed where the time and trust leak out, and why people default to interrupting a human even when the answer is written down somewhere.
- Step 1Question hits
Someone needs to know 'what's our refund policy for enterprise?' mid-task.
- Step 2Wiki searchpain point
Searches the wiki and gets 40 results. The top ones are from a policy that changed last quarter.
- Step 3Doc spelunkingpain point
Opens five docs, skims for the relevant clause, isn't sure which doc is canonical.
- Step 4Slack the channel
Gives up on docs, asks in #ops. Waits. Gets two conflicting answers.
- Step 5Ping the expertpain point
DMs the one person who definitely knows. Interrupts their deep work.
- Step 6Answer (maybe)pain point
Gets an answer 40 minutes later. It's unverifiable, uncaptured, and the next person will repeat the whole thing.
What the interviews clustered into
Observations across all six interviews affinity-mapped into four themes. Each one is a reason the current model fails the asker, the expert, or the truth.
Search ≠ answer
People don't want a ranked list of documents to read. They want the answer to their actual question, with the source attached so they can trust it.
Staleness kills trust
One wrong, out-of-date answer poisons the whole base. After it, people stop looking and go straight back to interrupting humans.
Experts are the index
The real search engine is the colleague who knows. Knowledge lives in heads, not systems, so it walks out the door and doesn't scale.
Answers vanish
Every answer is given once, in a DM or a thread, then lost. The same question gets re-answered indefinitely because nothing is captured.
Three insights that drove the design
The deliverable is a cited answer, not a result list
The unit of value is a synthesised answer to the question asked, with its sources attached. A list of documents puts the work back on the asker, and an uncited answer is unusable in an enterprise.
→ Answer + provenance, always (Principle 1)
Trust is a freshness problem
An answer is only as trustworthy as its sources are current. The system has to show its sources, show their dates, and flag when it's unsure. Otherwise it inherits the wiki's credibility problem.
→ Show sources & freshness (Principle 2)
Every answer should make the next one easier
Answering a question should improve the system, not just resolve one ticket. Capture turns a one-off interrupt into reusable institutional memory.
→ Capture compounds (Principle 3)
★ key insight
People don't want better search. They want an answer they can trust and cite, and they want answering it once to mean nobody has to answer it again.
Where company knowledge actually lives.
The knowledge sprawl
I mapped every place an answer might be hiding in a typical company. The problem is the scatter: the same truth is spread across systems that don't talk, half of it undocumented, and the only thing connecting them is a human who happens to remember.
No system holds the answer. It's smeared across a dozen tools and a hundred heads, and the index is whoever's been here longest.
Heuristic evaluation: the two incumbents
I evaluated the two tools companies reach for, enterprise wiki search (Confluence-style) and a generic AI search bolt-on, against six heuristics to locate the systemic gaps a real knowledge engine would have to close.
Competitive teardown
Six tools across the category, scored on eight capabilities. The pattern is clear: search tools return documents without synthesis, and AI bolt-ons synthesise without provenance. Nothing combines a cited, synthesised answer with freshness signalling and a capture loop.
| Capability | Almanac | Confluence | Glean | Guru | Notion AI | ChatGPT Ent |
|---|---|---|---|---|---|---|
| Synthesised answer | Yes | No | Yes | Partial | Yes | Yes |
| Inline citations | Yes | No | Partial | Partial | No | Partial |
| Freshness signalling | Yes | No | No | Partial | No | No |
| Indexes all sources | Yes | No | Yes | Partial | Partial | Partial |
| Confidence on answers | Yes | No | No | No | No | No |
| Capture / reuse loop | Yes | Partial | No | Yes | No | No |
| Gap visibility (admin) | Yes | No | Partial | Partial | No | No |
| Built for the asker | Yes | Partial | Partial | Partial | Partial | Partial |
The gap statement
No existing tool gives a cited, synthesised answer with freshness signalling and a capture loop. Search returns documents, and AI bolt-ons hallucinate confidently. The opportunity is the trustworthy middle: an answer you can verify, that gets better over time.
The hypothesis.
Positioning
Almanac is an enterprise AI knowledge engine. You ask a question in plain language; it returns one synthesised answer assembled from your company's own sources, every claim cited and dated, with a confidence signal and a one-click way to capture the answer for the next person. It is not a wiki, not a search engine, and not an ungrounded chatbot.
what it is
- An answer engine: synthesised responses, not document lists
- Grounded entirely in the company's own sources, always cited
- A capture loop that turns answers into institutional memory
what it's not
- Not another wiki to keep up to date by hand
- Not keyword search returning forty blue links
- Not an ungrounded chatbot that answers from thin air
The question-centric mental model
The core IA bet: structure the product around the question and its answer, not around documents and folders. People arrive with a question, and the system's job is to resolve it from grounded sources and leave behind a reusable, cited answer. Documents become evidence in service of an answer, not the thing you navigate.
Four design principles
Each principle is a tension resolved in a direction, and each traces directly back to a research insight.
Answer with the source attached
Never an answer without provenance. Every claim links to the exact doc, thread, or ticket it came from, so verification is one click, not an act of faith.
From insight: the deliverable is a cited answer.
Surface freshness, surface doubt
Show each source's date and flag when the system is unsure or the sources conflict. An honest 'I'm not certain' beats a confident wrong answer every time.
From insight: trust is a freshness problem.
Every answer compounds
Answering a question improves the system. Capture, confirm, and reuse turn a one-off interrupt into durable institutional memory.
From insight: every answer should make the next easier.
Ask like a person, not a query
Plain-language questions, not boolean search syntax. The interface meets people where they are: mid-task, in a hurry, thinking in questions.
From insight: search ≠ answer.
How it thinks: architecture & flows.
The knowledge lifecycle, as tasks
Before any IA, I broke the knowledge lifecycle into discrete tasks with their dependencies, so the structure would serve the flow of a question, not the storage of documents.
Card sort: how people group knowledge
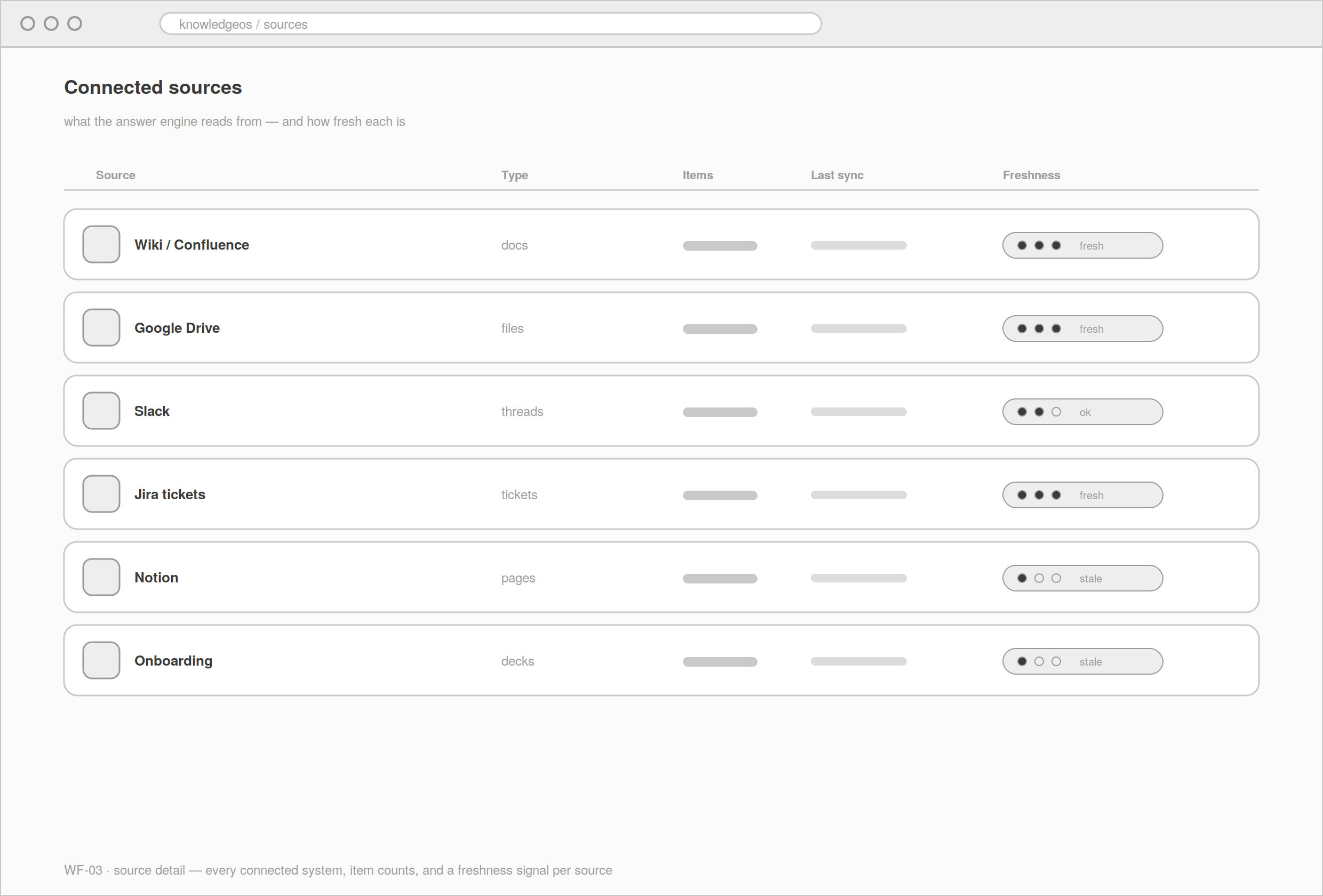
An open card sort with eight employees tested whether people think in questions or in documents. They think in questions. Participants grouped tasks by 'what I'm trying to find out', not by document type or department. The sort also settled the top-level surfaces: Ask, Sources, Saved Answers, and an admin Insights view.
Participants
8 employees
Method
Open card sort
Result
Question-first grouping confirmed
Bonus
Settled the 4 top-level surfaces
Three IA decisions
Ask is the home
Chose: Made the ask-and-answer surface the default landing view. The product opens on a question box, not a folder tree.
Considered a browsable knowledge-base home (rejected: it reproduces the wiki people already route around).
Provenance as a panel, not a footnote
Chose: Sources live in a dedicated, always-present panel beside the answer. Provenance is a standalone surface, not a hover-state afterthought.
Considered superscript footnotes (rejected: too easy to ignore, and verification needs to be visible, not buried).
Capture in the answer, not a separate tool
Chose: Saving and confirming an answer happens inline, right where the answer appears. The capture loop has zero friction.
Considered a separate 'contribute to wiki' flow (rejected: friction is why knowledge never gets captured today).
Building it.
low-fidelity wireframes
Low-fidelity, greyscale wireframes first, to lock structure and the trust patterns before any colour or brand. The questions at this stage: how do an answer and its sources sit together on screen, how does a citation read at a glance, and how do freshness and confidence show without shouting?
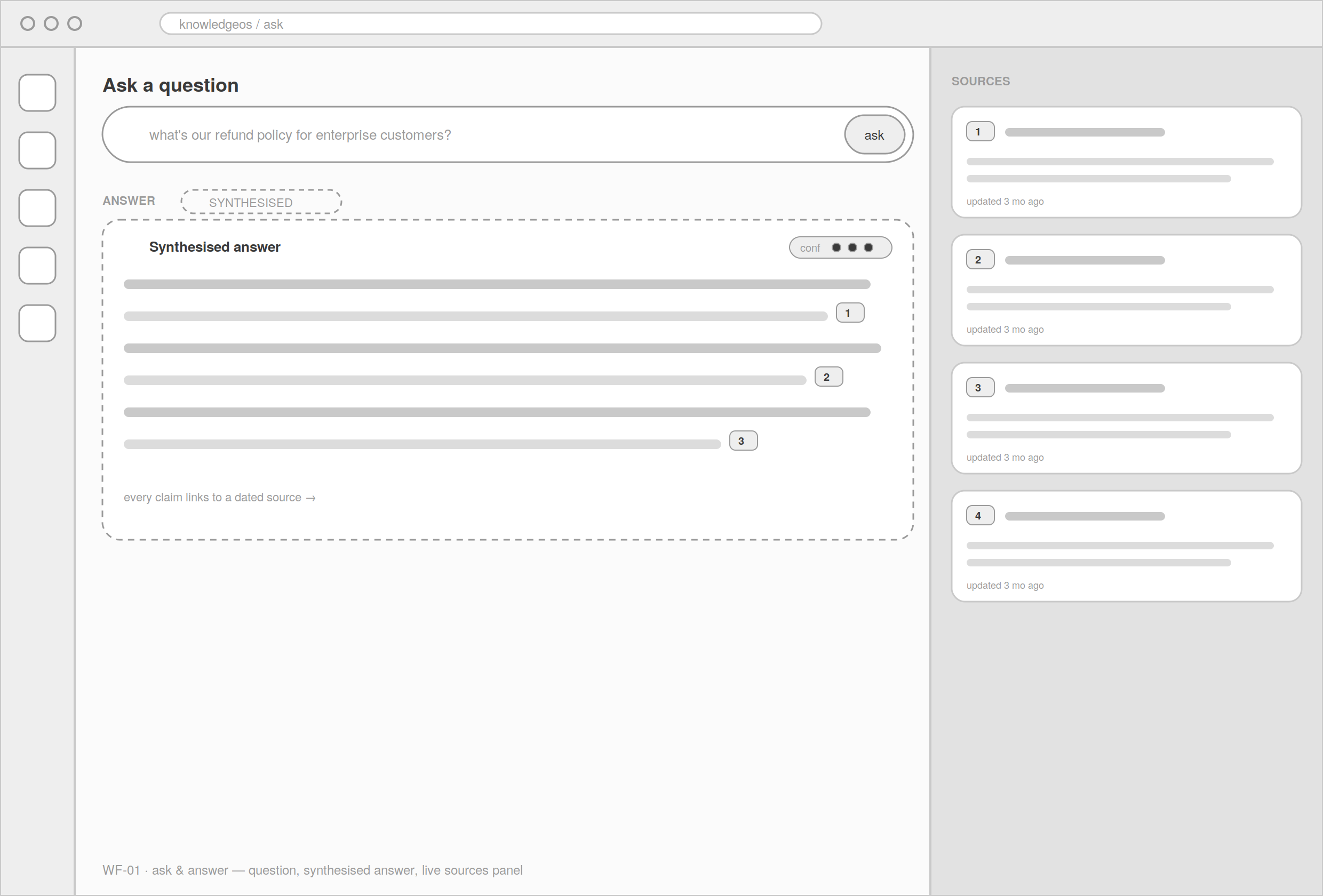
Ask & answer
The signature view in greyscale: question box up top, synthesised answer in the centre, sources panel on the right. Locked the answer-beside-provenance relationship before any styling.
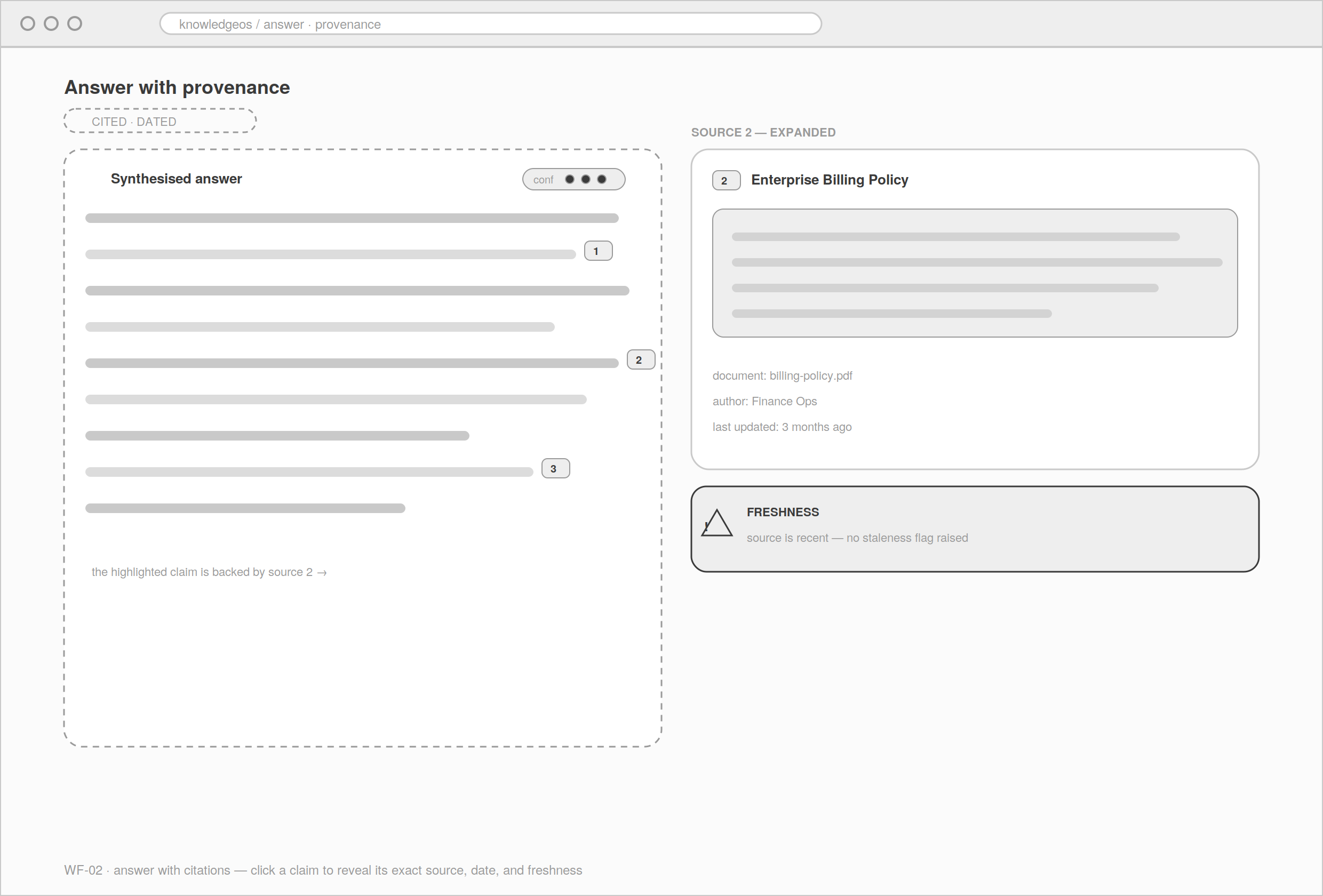
Answer with citations
The trust moment, structurally: every claim carries an inline citation marker that ties to a dated source card. Provenance rendered as a dedicated panel beside the answer, not a footnote.
Source detail
Expanding a citation reveals the exact passage, its document, and its date, plus a freshness flag when the source is old. Verification in one click.
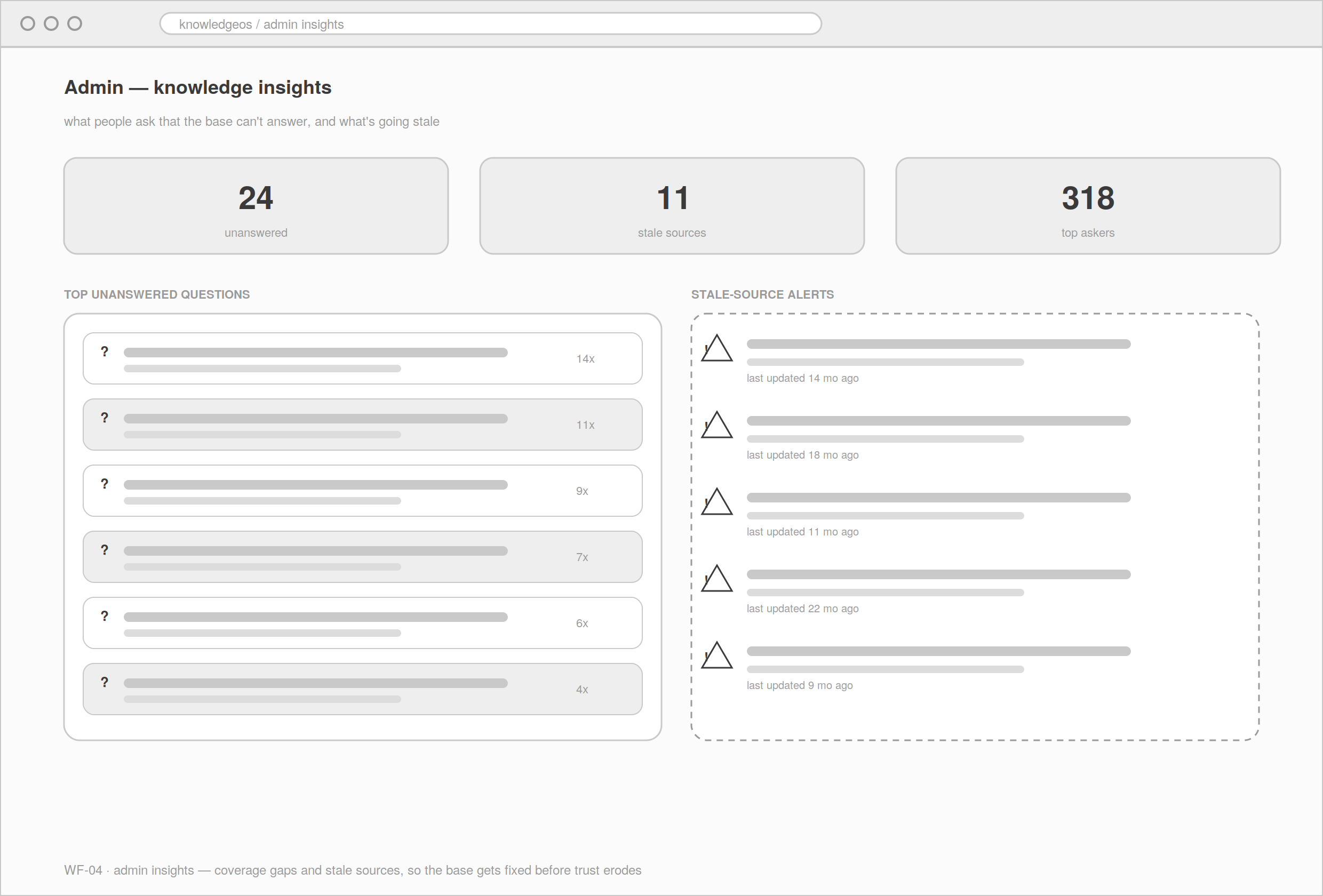
Admin insights
What's being asked that the base can't answer, and which sources are going stale. Turns the knowledge admin from a janitor into a gap-fixer.
Three core task flows
Three flows carry the product, each with its AI touchpoints and trust gates marked. The gates are the point. The system synthesises freely, but always exposes its sources and its uncertainty before the user acts.
Ask → Cited answer
Question asked → sources retrieved across systems → AI synthesises → answer rendered with inline citations + confidence → user verifies provenance. AI touchpoints: retrieval, synthesis. Trust gate: every claim cited and dated.
Answer → Verify source
Read answer → click a citation → exact source passage + date shown → freshness flag if stale → user trusts or digs deeper. AI touchpoint: retrieval ranking. Trust gate: source and date always visible.
Answer → Capture
Good answer → confirm/save inline → answer becomes reusable institutional memory → next asker gets it instantly. AI touchpoint: dedup + linking. Human gate: a person confirms before it's canonised.
the live prototype
The wireframes locked the trust architecture; these screens give it a face. What you're looking at is a live, clickable prototype of the ask-and-answer surface: a teal gradient marking every synthesised claim, numbered citation chips linking each sentence back to its source, and freshness dates that make staleness visible instead of silent. Open it, ask a question, click a citation, and see the provenance trail for yourself.
key screens
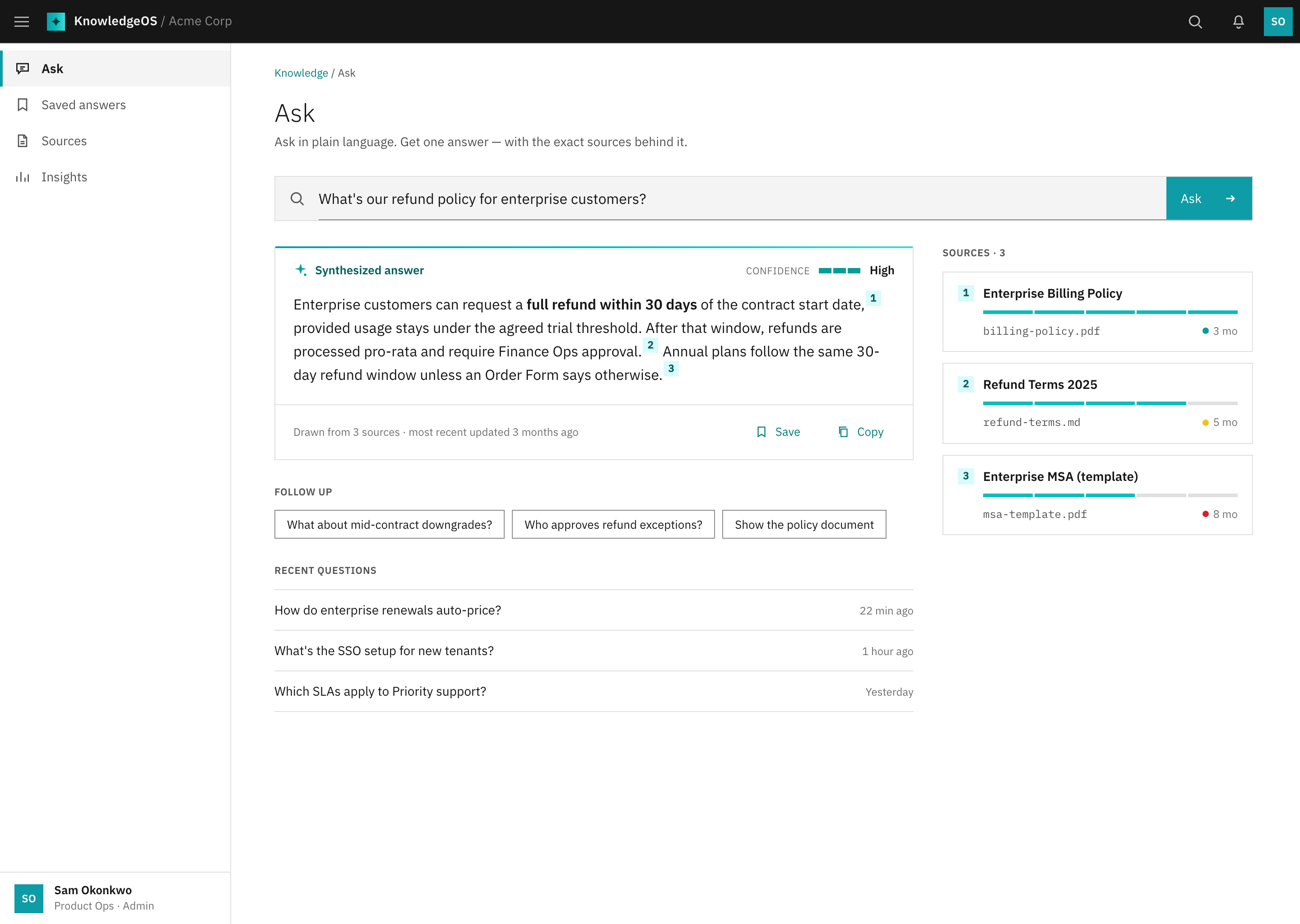
Ask & answer
The hero. A plain-language question returns one synthesised answer with inline citation chips, a confidence signal, and a live sources panel. The colleague-interrupt, replaced.
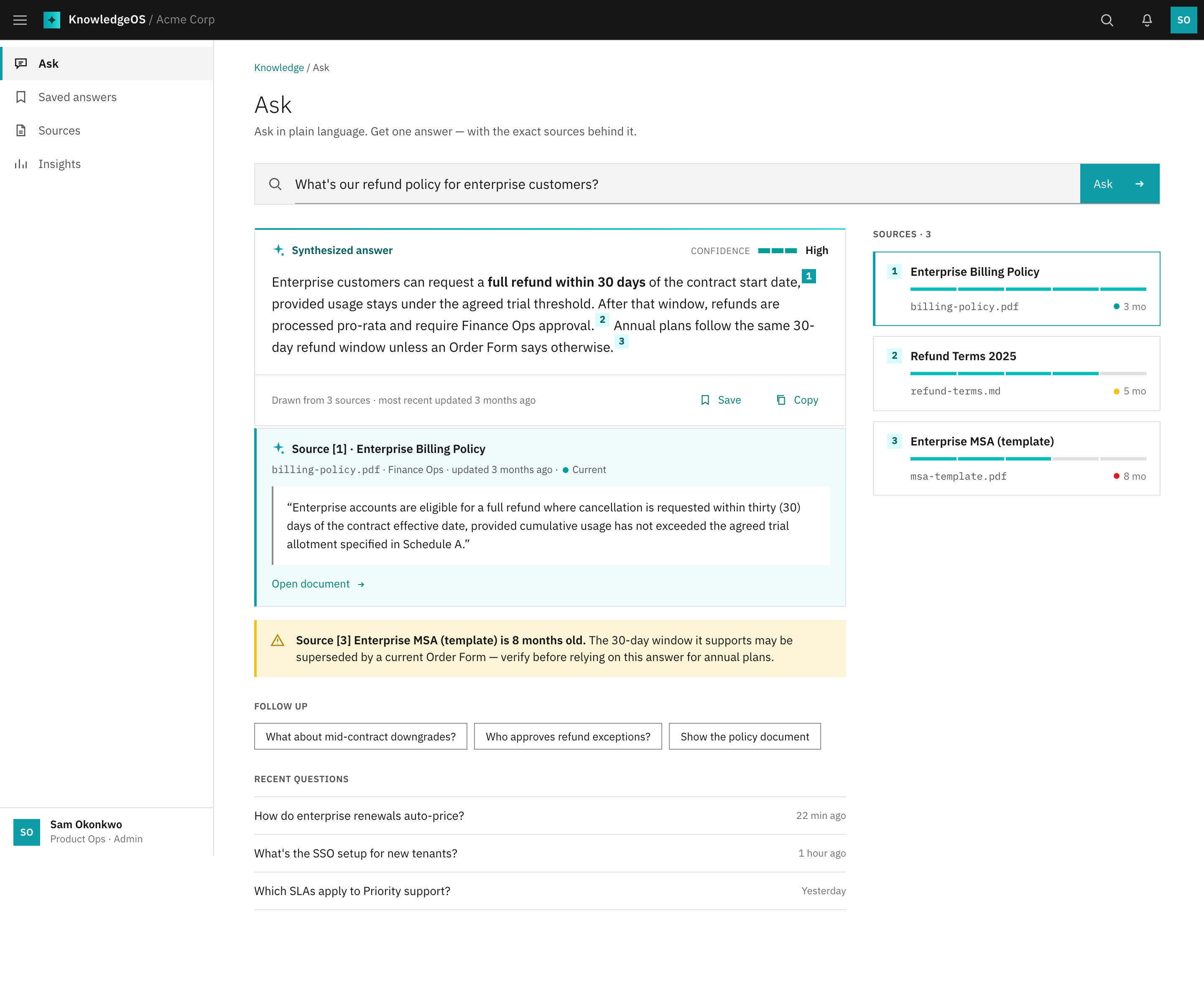
Provenance open
Click any citation and the exact source passage expands: document, author, and date, with a freshness flag when the source is ageing. Trust made tangible.
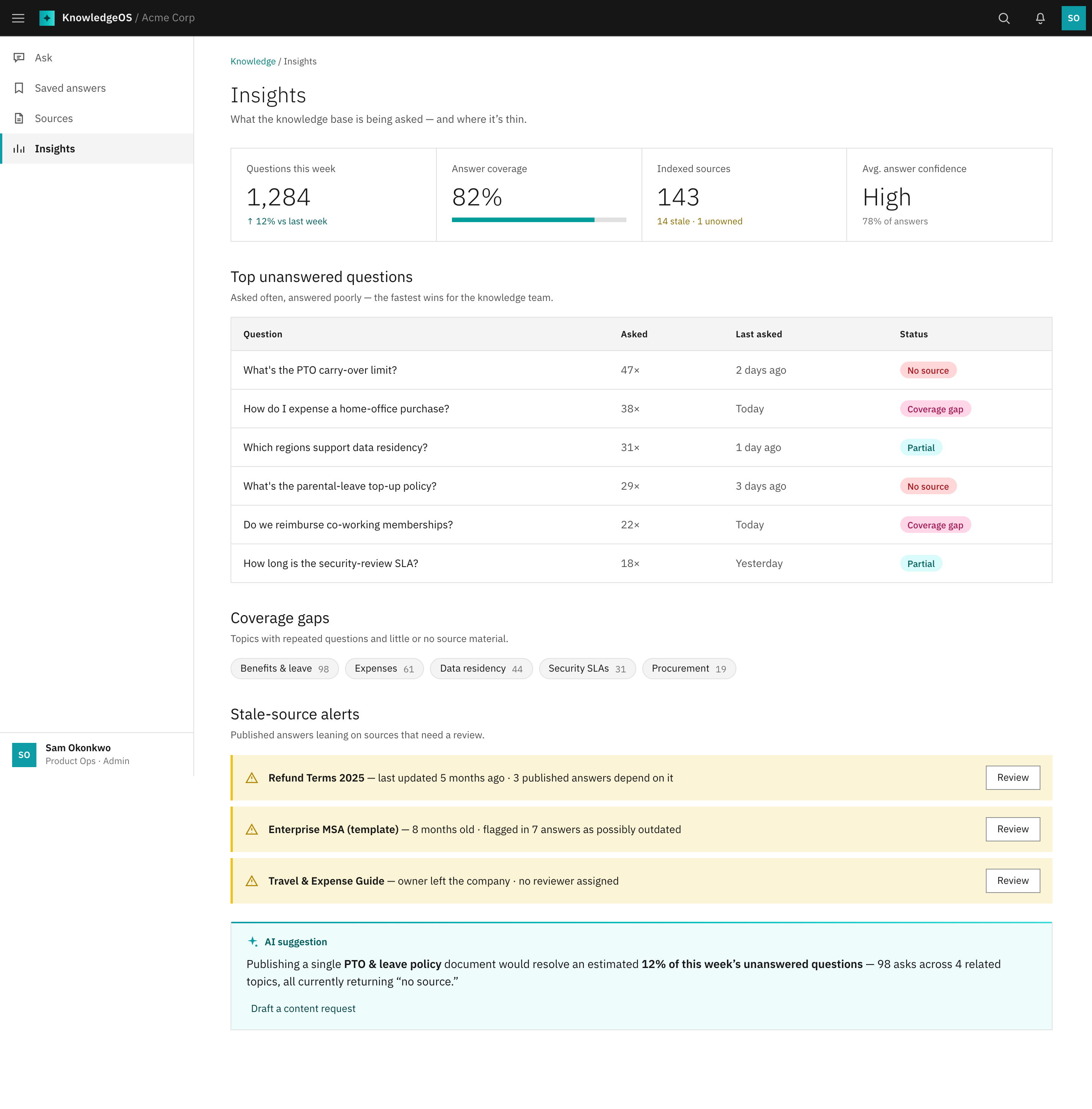
Admin insights
The knowledge admin's view: top unanswered questions, coverage gaps, and stale-source alerts, so the base gets fixed before trust erodes.
Why anyone would trust an AI answer.
Every enterprise has tried an AI search bolt-on. Most get abandoned within weeks, not because the answers are wrong, but because there's no way to tell whether they're right. Almanac treats that verification gap as the core design problem, not an afterthought. Five interaction rules govern every synthesised surface, and they all serve one outcome: the reader can check the machine's homework without leaving the screen.
Nothing unsourced
Every sentence in a synthesised answer traces to a specific passage in a specific document. If the retrieval can't ground a claim, the claim doesn't appear. The rule is absolute.
Dates visible at the point of trust
Each citation carries its source's last-updated date right next to the claim. An 18-month-old policy and a yesterday-refreshed handbook look different, and they should.
Answer first, evidence beneath
The synthesised response is the fast path; the full source passages are one click below it. Glanceable for the person in a hurry, expandable for the person who needs to be sure.
Experts can correct
A domain expert who spots a wrong answer can flag or fix it. That feedback sharpens retrieval and marks bad sources, closing the loop between the people who know and the system that serves.
Honest about gaps
When the sources don't contain an answer, the system says 'I can't answer this from what's indexed' and surfaces the gap to the admin. Silence is better than invention.
Three decisions that shape trust
Teal means 'the AI wrote this'
A teal gradient and the ✦ marker appear only on synthesised content. Raw source documents never carry either. The separation is instant and unambiguous, so no one has to wonder whether they're reading the machine or the original.
Citations woven into reading
Numbered chips sit inside the answer text, at the point of each claim, not footnotes at the bottom of the page. Verification becomes part of the reading act, not a separate task.
Staleness as a visual signal
A source dated six months ago looks visibly different from one refreshed yesterday. The freshness flag sits next to the citation, where the trust decision actually happens.
A system built for reading, not browsing.
Most enterprise tools are built for workflows: forms, tables, dashboards. Almanac is built for reading. Someone arrives mid-task, reads a paragraph, checks a source, and leaves. The palette is muted, the typography is generous, and the whitespace is aggressive, so a synthesised answer reads like a reference document you'd trust, not a chat bubble you'd screenshot and doubt. Teal is the only colour that carries weight, and it marks every AI-synthesised surface.
color foundations
typography scale
spacing scale (8pt grid)
design tokens
| Token | Value |
|---|---|
| color.surface.bg | #F6F8F8 |
| color.ink.900 | #15201F |
| color.brand.teal | #0E9CA6 |
| gradient.ai | 120deg,#0E9CA6,#2BB6B0,#6FD7C6 |
| radius.md | 12px |
| radius.lg | 20px |
| shadow.card | 0 1px 3px rgba(15,40,40,.08) |
| icon.ai | ✦ sparkle |
component library
A Material-grade component set, extended with the AI-specific pieces that make the product trustworthy. These are the patterns that carry the confidence-and-provenance language across the OS family.
system outcomes
The visual hierarchy serves one job: make the answer easy to read and the sources easy to verify. Teal and the ✦ appear only where the AI has synthesised. Raw source documents never carry either. A reader glancing at the screen can separate the machine's words from the company's own, without reading a label. That separation is the foundation of every trust pattern in the product.
a shared OS-family base
Almanac sits between Slate (action-oriented, dense tables) and Crux (analytical, data-heavy) in the same family of three. Where those two lean on scanning and comparing, this one leans on reading and verifying. It takes the shared spacing and motion tokens but pushes the type scale larger, the palette cooler, and the information density lower. Same bones, different posture.
Built this far.
A concept case study can be rigorous without pretending it shipped. Here's what exists, what it's designed to prove, and what would come next if this moved from portfolio to product.
The artifact
- Discovery research grounded in real questions: tracing the life of a question through an org, mapping where answers actually live, and identifying the colleague-interrupt as the true competitor.
- A competitive teardown across six tools, exposing the gap between search (returns documents) and AI bolt-ons (answer confidently without citations).
- A question-centric IA validated by a card sort, structured around what people are trying to find out, not where documents are stored.
- Three core task flows (ask → answer, answer → verify source, answer → capture) with trust gates at each AI boundary.
- A clickable prototype of the full loop: ask, cited answer, provenance drill-down, and save. It proves the trust architecture holds together in use.
Bets the design is making
Hypotheses to test, not results to claim.
A cited answer beats a colleague DM
If provenance is visible and sources are dated, will a mid-level employee stop interrupting the expert and trust the system instead? That's the make-or-break question, and it needs real users against a real corpus to answer.
Freshness flags change behaviour
Does seeing '8 months old' next to a source actually make someone distrust the answer appropriately, or do they ignore the date? A controlled study with mixed-freshness sources would surface this.
Capture compounds over time
The loop where saving an answer improves the base for the next asker is the long bet. Whether it compounds or gets abandoned is a longitudinal question: weeks of use, not a walkthrough.
If this were real.
Moving Almanac from portfolio piece to real product means answering questions the prototype can't. Does the trust architecture survive a messy, stale, contradictory corpus? Do real people stop pinging the expert? Here's the path.
The next chapters
Test the trust model
- →Usability testing of the prototype against domain experts and knowledge seekers. Do inline citations actually earn enough trust, or do people still reach for the Slack DM?
- →Concept-test the hard edges: what happens when two sources contradict, when a source is 18 months stale, when the system says 'I can't answer this'? Those are the moments that build or break confidence.
Prove retrieval, not just UI
- →Wire the prototype to a real, messy corpus of outdated policies, contradictory docs, and buried Slack threads, then measure citation accuracy. A beautiful provenance panel over wrong retrieval is still wrong.
- →Bring a knowledge admin into the loop early and test the maintenance side: does gap detection catch real gaps? Do stale-source alerts trigger re-indexing before trust erodes?
Pilot with a small team
- →Deploy to a single team for real daily use over weeks. That's the only way to learn whether the capture loop compounds or gets abandoned, and whether the colleague-interrupt actually falls off.
- →Measure the design bets from 'Built this far' against observed behaviour, not walkthroughs.
Scale what works
- →Multi-team rollout, connectors for real source systems (Drive, Confluence, Slack), and the retrieval edge-cases that only surface at scale: conflicting policies across regions, access-controlled documents, multilingual corpora.
Where this leaves off
Almanac is a researched, designed, prototyped answer to a problem every company has and nobody has solved cleanly. The next step is the hardest: a real corpus, real questions, and real experts deciding whether a machine's answer, with its sources attached, is good enough to stop the interrupt. That test is what I'd run first.
more concepts
the rest of the OS family →
thank you for reading.
Almanac is a self-initiated concept. If you'd like to talk through the process, or where it goes next, I'd love to connect.